

【题图取自Equestria Daily】
自上次语音合成网站15.ai下线更新已经过了数月之久,在大家的期待下,站点终于带着一大批新角色(不仅限于小马角色)重新上线!
在最近的一次更新中,15.ai对网站的UI做了微调,并添加了赞助渠道以及去噪功能。在生成语音后还会显示AI生成的该条语音的校准置信度(75%以上为优秀)。此外站点还去掉了原有的情绪选择功能,将其改为根据上下文自动选择情绪。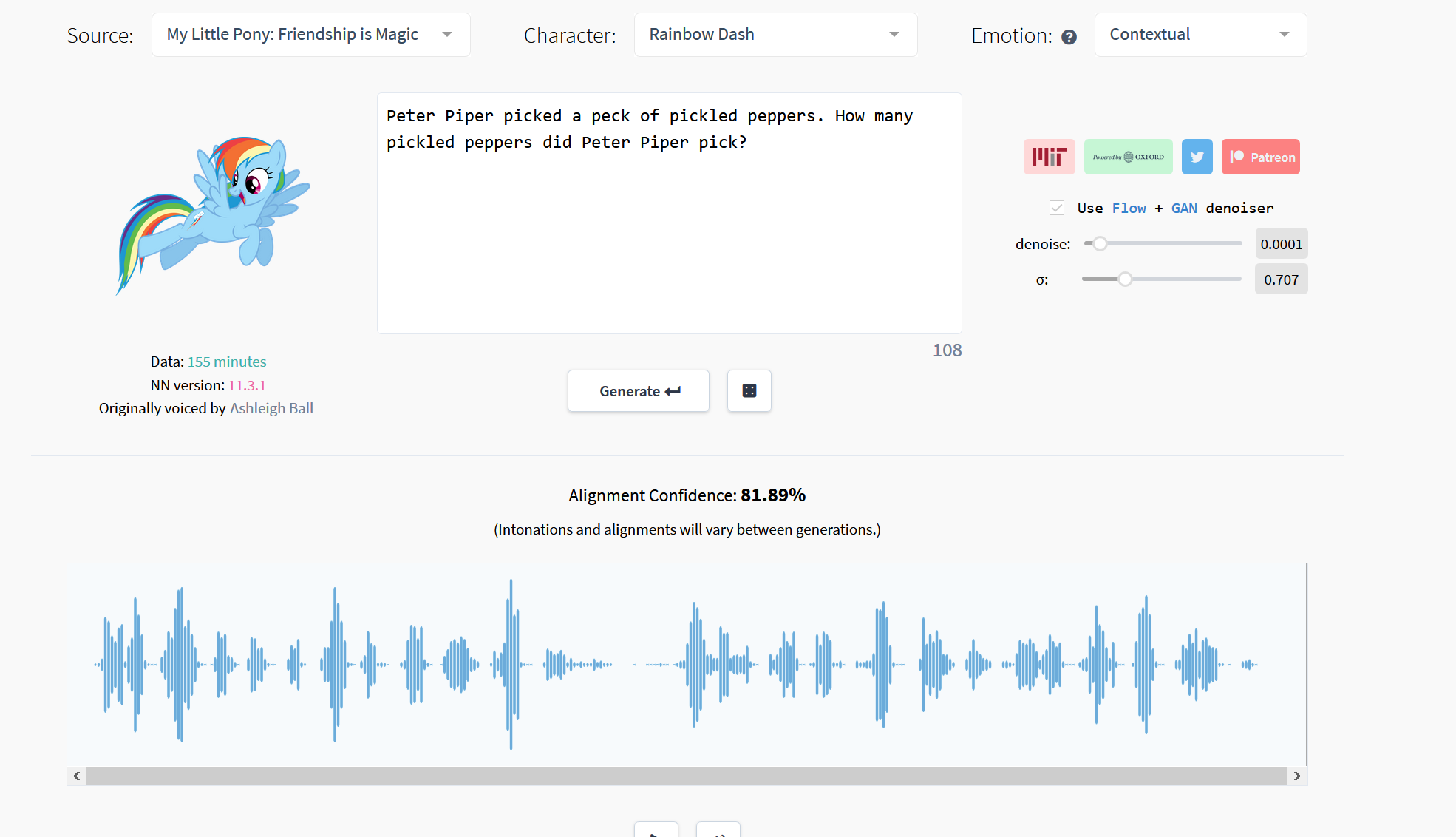
本次更新包含了:
- 提高角色音频质量,引入全新去噪机制(可显著提高所有角色的音频质量)
- 引入大量新角色(不仅限于小马角色,下文中仅列举已有小马角色)
- 网站UI优化
- TTS模型(文本转语音)支持使用emoji表情改变句子的语气
该去噪机制是基于GAN生成对抗网络并结合TensorFlow改进的的Flow/GAN混合网络,可以显著提高生成的音频质量(该网络同样适用于图像去噪均属于深度学习范畴)。虽然站点上已经加入了去噪相关的参数滑条,但目前去噪的开启状态和参数均不可修改。
现在共计有45位小马角色支持语音生成了,分别是:
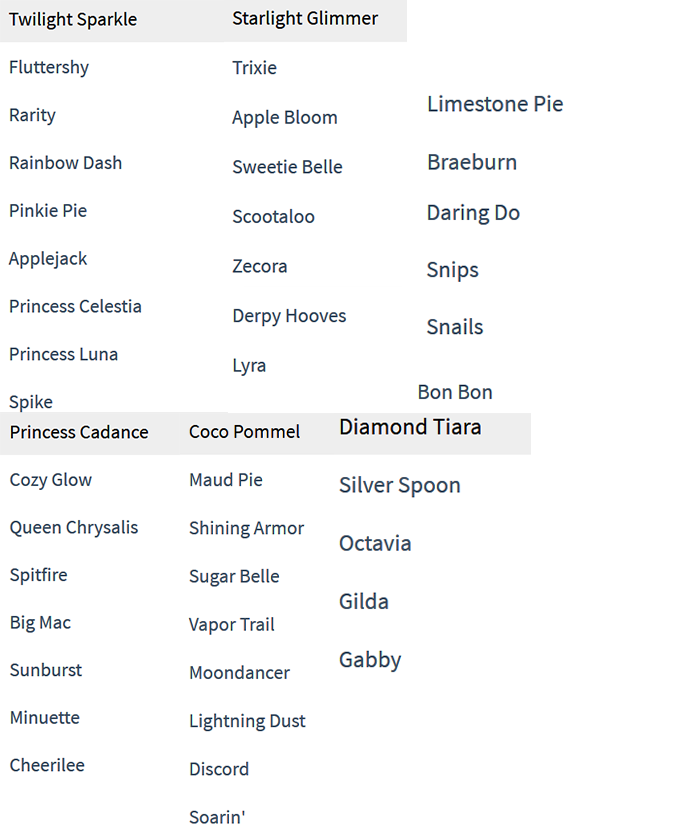
新添加的小马国女孩角色共有四个(尽管每个角色只有几十秒到几分钟的训练时间,但生成的语音依然可以达到80%的可信度:
- Sunset Shimmer
- Adagio Dazzle
- Aria Blaze
- Sonata Dusk
15.ai使用的TTS算法目前已经更新到v11.2.x,这是语音克隆和语音合成领域最前沿的算法,该算法通过使用字典查找表将每个英语单词分解成各自的音素。该算法使用字典查找表是由牛津词典API、Wiktionary和CMU发音词典拼凑而成的。这其中也包含了现代新兴词汇,采集自各大网站互联网,其中包括谷歌、reddit、4chan和城市词典(urban dictionary)。如果该算法遇到了一个词典表中不存在的单词,则将使用从LibriTTS数据集的训练中学到的语音规则来推断该单词的发音。
此次更新并加入了表情分析“emoji analysis”的功能。该功能基于MIT的DeepMoji项目,可以将文本背后的感情用emoji表达出来,借此控制输出的语音该偏向何种情绪。接下来TTS模型能够基于emoji产生带有情感的语音。除此以外,该模型能通过同时训练多个角色来显著减少所需训练时间(原模型每个角色需要单独训练),实验表明,在同时支持多声道嵌入和情绪感知的情况下,仅需15秒的语音数据该模型就可以克隆出真假难辨的声音。
如需更多信息也可参见15.ai官网
动画企业有配音着落了艹
好耶!除了自动识别情绪感觉还没有手动选择好之外其他都好棒。
但是为什么我这边总显示下限维护呢,不会要魔法上网吧?
情绪化处理需要怎样输入才能使用,之前试了半天都无法处理
那个是自动根据你词汇分辨情绪来改变你句子语气 你啥都不用设置
超棒!!!
怎么没看见有ss呢
而且我发现居然有半条命里戈登弗里曼的声音,他还会讲话的?
在马国女孩那个角色里有ss和海妖
那个是彩蛋,不论输入什么都返回没有声音
ss归到小马国女孩里了
好耶
平常进不去,好像需要科学上网才能用
可以使用,就是比较卡
之前大概6.0版本时网站开过一些时长,那会就已经有了这么多角色了。现在关于小马的角色我不知增加了多少,但是其他角色增加了许多。
还有那个APHAbet到底是什么样的原理呢?如果可用,可否利用那个来说出尽可能准确的中文发音呢?
ARPAbet是上个世纪70年代DARPA为了研究方便设计出来的标音方式,针对的是美式英语,想要描绘汉语发音可能还是有困难的。
具体来讲的话是用一个或两个特定的字母和IPA中的音标对应,用字母以外的符号(数字一类的)表示重音等信息。具体的和IPA的对照可以参考ENWP的页面(https://en.wikipedia.org/wiki/ARPABET)。另外CMU词典可以直接查英语单词发音的ARPAbet写法(http://www.speech.cs.cmu.edu/cgi-bin/cmudict)。
感谢科普。。。才发现那个ARPA还是APHA的拼错了。
刚刚试过了,确实很厉害???
看到了一大堆的机器学习算法,默默地流下了不学无术的眼泪
好几天前就恢复了